
From 20 Thousand to 20 Million
Penetrating Silicon Valley with any idea from Slovenia is difficult, but developing a system to recognize over a million images is even harder. Every algorithm has humble beginnings accompanied by failures. Usually, the development of such algorithms is based on an empirical method. Reveel1 is no exception here. We developed an algorithm that worked perfectly on a database of 20,000 images, but problems arose with server query speeds and processing concurrent queries, which prevented expanding the database to a million images. It turned out that solutions from the field of distributed systems could solve this problem.
Introduction
At Reveel, we build solutions that enable publishers and advertisers to make their visual media interactive. One of these solutions is an image recognition system that allows us to connect the physical world (print media) and the digital world (mobile application, website). Print media are inherently non-interactive, but with the help of image recognition in print media, the user accesses interactive content online using their favorite mobile device or computer.
Of course, the problem we are solving now differs from the problem and idea for which we founded the company. The original idea was how to simplify shopping via television. We were developing a mobile application that would allow users to quickly and easily buy whatever they saw on the screen while watching movies or TV shows. The technical problem we tackled was how to use sensors in a smartphone to detect what the user is watching on a television, canvas, or monitor.
Beginnings
During our research, we realized that the problem could be solved in three different ways:
-
Manual search - Require the user to manually search for and select the content they are watching. This would solve the problem exclusively with standard user interface solutions. Such a solution would require the least development time, but with increasing content in the system, it would become tedious for the user.
-
Audio recognition - Enable the recognition of video content via its audio tracks. The advantage of this approach is a smaller initial database, as the audio track of a video is smaller than its video track. Another advantage regarding user experience is ease of use, as the mobile device can be held in a comfortable position while it recognizes the audio.
-
Video recognition - The main advantage of this approach is that it has much greater potential for the future, as it is not limited only to video content; the technology can also recognize magazines and other print media.
While both audio and video recognition approaches have their strengths and weaknesses, the main factor in our decision for video recognition was to differentiate ourselves from our competition.
Digital Watermark
The initial idea was the use of digital watermarks2 in videos. We encoded digital watermarks into the video, captured an image using the camera on a mobile device, decoded the digital watermark, and thus identified the video.
Digital watermarking is a process where data is written into the entire image. It is important that the distortion is imperceptible to the human eye but visible to the decoding algorithm, which calculates an N-bit code from the image that uniquely identifies the content. Of course, the digital watermark is not detected on the original image, but on an image captured by the mobile device’s camera that contains this original image. Therefore, the algorithm must have high noise tolerance.
High noise tolerance can be achieved by using high data redundancy during the encoding of the digital watermark, but this means we are limited by the amount of data that can be encoded into the image. Inserting a digital watermark into video content involves encoding an N-bit code through all frames of the video, where the first X bits uniquely identify the video content, and the other Y bits represent the temporal location within the content. When capturing an image of the video via a mobile device, registration of the television or monitor edges is performed first, followed by perspective correction of the captured image, and then extraction of the digital watermark data.
Our first prototype was the algorithm described in the article by Meerwald et al.3, with which we could encode 56 bits into an individual image, where the first 32 bits identified the content and the remaining 24 bits represented the timestamp in the content. The watermark insertion algorithm uses a discrete wavelet transform to encode data into the original image using “spread spectrum” coding.
During testing, we found that the efficiency of the algorithm is highly dependent on the success of the television or monitor edge registration. We performed edge registration using a combination of several algorithms: Canny edge detection, the Hough transform for finding lines, and then we looked for the most suitable corners based on the criterion that intersections must have an internal angle of around 90 degrees.
Before we could continue development and research, we realized that our solution was not the most suitable for the market in which we wanted to launch our solution. The solution required modifying the video content, as we had to insert a digital watermark into it, which would mean we would have to purchase a license for every piece of content into which we wanted to insert a watermark. From a marketing and sales standpoint, this approach proved to be unfeasible or very expensive.
Features, Clustering, and Weights
Due to market demands, we were forced to change our approach and figure out how to recognize content without altering it. During our research, we came across a field of algorithms collectively known as Content-based Image Retrieval4 or CBIR. These algorithms work by first creating a database of images and then enabling searches within that database. The search finds the image in the database that best matches the queried image.
In implementing our CBIR solution, we decided to use an approach where we extracted features from images and then used these features for building the database and searching. When choosing features, we looked for ones that would be robust to distortions and noise that occur in an image when the target image is captured by a mobile device camera.
Another requirement imposed by video recognition constraints was the speed of the algorithm. The entire query must be executed quickly on the server to ensure that the video content is recognized in a reasonable time for the user. Due to these constraints, we decided to use ORB features5 (Oriented FAST and Rotated BRIEF). The algorithm is sufficiently robust to transformations and noise and yet very fast. Above all, we were convinced by the fact that the algorithm is not licensed and can be used freely.
Then came the second problem: how to successfully perform a search over a database of features. To simplify, we have two sets of features: the first set represents features calculated from all images in the database, and the second set represents features calculated from the image used for the search. In practice, the second set contains between 1,000 and 2,000 features, while the first set contains around 28 million features. It quickly became apparent that a simple linear search through the database was unfeasible, mainly due to the time constraints we have for queries.
While researching solutions that satisfy all constraints, we came across the FLANN67 group of algorithms (Fast Library for Approximate Nearest Neighbors), which enable fast searching through large databases of binary or vector data. ORB features are in binary format, so we decided to use Hierarchical Clustering trees.
Using the FLANN approach, we could quickly find all features that best matched the search set of features. However, we encountered another problem that arises when capturing an image with a mobile device – most features of the original image change despite the robustness of the ORB algorithm. This problem led us to the idea of implementing clustering, where we generalized all features to a predefined set of features (vocabulary). This approach sped up the search through the FLANN index and solved the problem of features distorted due to noise and artifacts.
After several months of trials and failures, we found an article by Sivic et al.8 titled “Video Google: a text retrieval approach to object matching in videos”, which pointed us in the right direction and laid the foundations for the current algorithm. The article describes a similar approach to the one we took ourselves but presents some key solutions that contribute to a working recognition system. The article describes a FLANN index built from a million pre-selected features, used to build a database. During a search, similar images are found in the database using the FLANN index, which are then reduced to a smaller set using TF-IDF9 weights. A linear geometric verification of key points is then performed on this set using the RANSAC algorithm.
With this algorithm, we can perform a search through a database of 20,000 to 50,000 images in less than 300 milliseconds, depending on the image content. We used this image recognition system in our product for a good year and a half until obstacles appeared that forced us to upgrade our system.
System Upgrade
The system, which was designed and implemented under great time pressure due to securing investment, eventually began to show signs of degradation. Initially, we only recognized video content, but over time we introduced more and more images of magazine pages and other print media into the system, which have different characteristics than video.
Problems arose with service availability during times of increased user traffic and when adding new content to the system. Processing times for individual requests increased from less than 300 milliseconds to 5 seconds or more, which is unacceptable for the user.
It was necessary to drastically reduce the search space searched by the server while retaining all existing images in the system. One solution to this problem is the implementation of a distributed system where not all servers have access to all data in the system.
We separated the server into two parts:
- Query server - accepts queries from the user
- Storage server - stores currently accessible images
There are usually multiple storage servers, and each holds only a part of all images currently in the system. With this approach, we effectively reduce the time required to process a query.
When we receive a query, it is sent to the query server, which then forwards this query in parallel using the RPC protocol to all storage servers. Each of the storage servers returns the identifier of the best image it has – if it exists – and a numerical weight indicating how confident it is that this image is the correct one. The query server then ranks the results and returns the best one to the user.
Judging by tests, this approach performs significantly better than the old one. However, it still has one problem. If, for any reason, one server becomes unavailable, users can no longer access that portion of the images.
The solution is to additionally replicate each of the storage servers N-times, thereby increasing redundancy for that portion of images in case any of these servers become unavailable. While this approach effectively solves the availability problem, it is important to emphasize that it introduces additional problems. It is crucial that all servers hosting a certain portion of images agree on what that portion is.
We thus arrive at the consensus problem, which is a known problem in distributed systems. There are many algorithms that solve this problem; the most famous among them is Paxos10, which is known for being very difficult to implement in the real world. Due to this fact, we decided to use the Raft algorithm11, which was designed to be easy to implement.
Architecturally speaking, we updated our system from a monolithic one, which contained query and storage functionality, to a distributed architecture where query servers (Q) communicate with multiple storage servers (S), each replicated for redundancy.
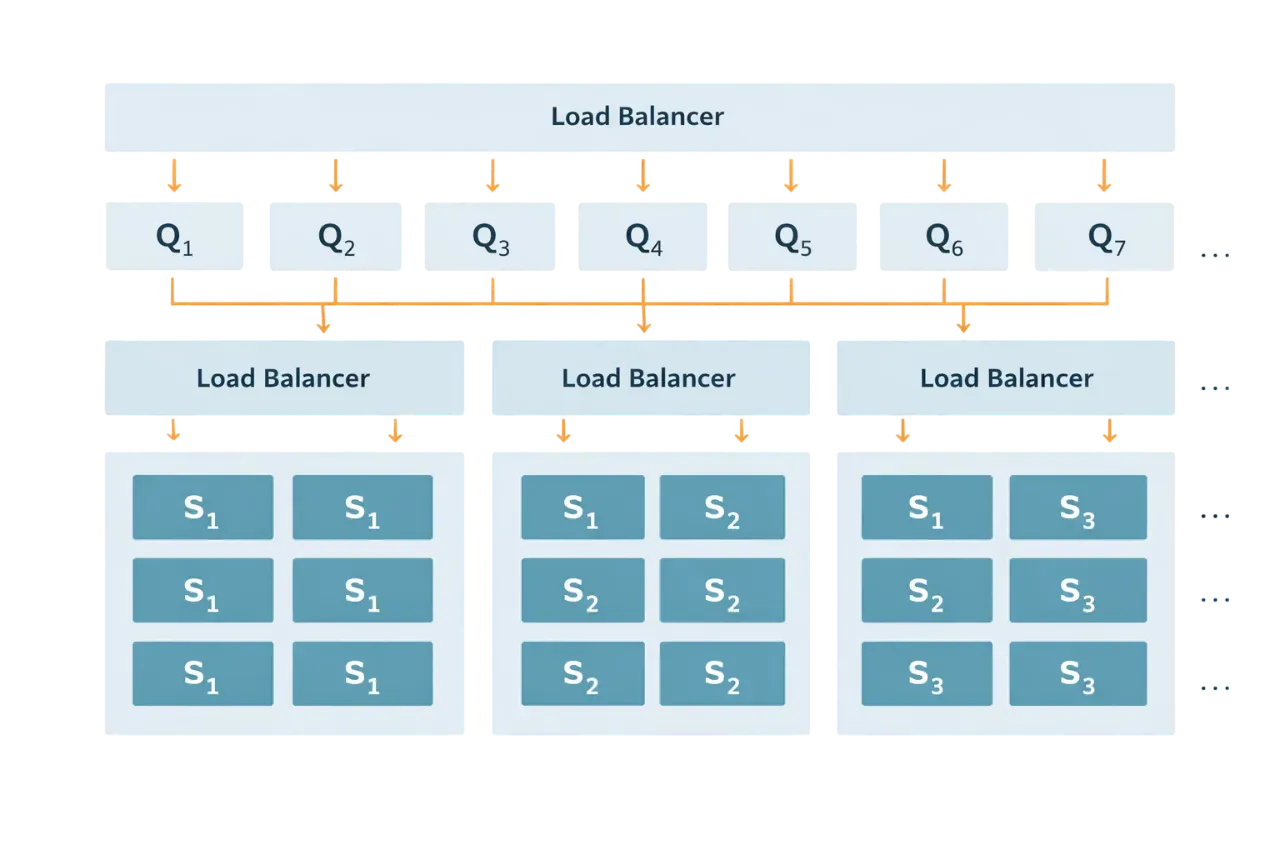
Figure 1: Architecture of the upgraded image recognition system, where Q are the so-called query servers and S are the so-called storage servers.
Future Challenges
Despite all improvements, we still have much to do before our system can recognize 20 million images. From developing additional features that will expand the system’s capacity, to improving existing algorithms. Given that Reveel is constantly adapting to the different markets we enter, the requirements of the recognition system will undoubtedly change, meaning that in the future we will encounter problems we haven’t thought of yet.
Caching
Our system processes an individual request in 300 milliseconds on average. Although this is very fast, it makes sense to store content that users access more frequently in a cache, as we can access it even faster this way and reduce the load on servers.
There are several ways to design a cache, and one of them is the use of hashing functions. In our case, we intend to use perceptual hashing functions12, which are capable of reducing the dimensionality of images to a few bytes while still preserving basic information about the image. This means that the results of the hash function for two similar images will also be similar.
Using hashing functions and Hierarchical Clustering trees, we can then build a cache that can quickly check if a query matches previous queries and, instead of repeating the search algorithm, return the result calculated in the previous query in advance.
Geometric Verification
An analysis of the steps of our recognition algorithm showed us that at least 50% of the time for each query is spent on the geometric verification of key points, which we solve with the RANSAC algorithm. This means that improving this step is crucial for the overall acceleration of the algorithm.
Since 1980, when the article for RANSAC was published13, many improvements have appeared; one of the better ones currently is Graph-Cut RANSAC14. GC-RANSAC uses principles from graph theory and, in one of the steps, builds a flow network graph from key points, over which it then performs cuts, thereby speeding up the search for inliers. According to the article, we expect approximately a 40% speedup by replacing the algorithm.
Conclusion
Four years ago, we started with a simple idea of how to simplify shopping for viewers of small and large screens. Over the years, this idea has changed many times, and with it, our solution has also changed. We quickly realized that failure is our best teacher and that we will only arrive at the right solution if we are willing to fail many times.
Footnotes
-
Reveel. Make all your media interactive so you can invite audiences to explore, learn and buy. https://reveel.it/ ↩
-
L. K. Saini, V. Shirvastava. (2014). A Survey of Digital Watermarking Techniques and its Applications. International Journal of Computer Science Trends and Technology, vol. 2, pp. 70-73. ↩
-
P. Meerwald, A. Uhl. (2010). Watermark Detection for Video Bookmarking Using Mobile Phone Camera. Communications and Multimedia Security, Lecture Notes in Computer Science, vol. 6109, pp. 64-74. ↩
-
W. Zhou, H. Li, Q. Tian. (2017). Recent Advance in Content-based Image Retrieval: A Literature Survey. https://arxiv.org/abs/1706.06064v2 ↩
-
E. Rublee, V. Rabaud, K. Konolige, G. Bradski. (2011). ORB: an efficient alternative to SIFT or SURF. Proceedings of the IEEE International Conference on Computer Vision, pp. 2564-2571. ↩
-
M. Muja, D. G. Lowe. (2009). Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. International Conference on Computer Vision Theory and Applications. ↩
-
M. Muja, D. G. Lowe. (2012). Fast Matching of Binary Features. Conference on Computer and Robot Vision. ↩
-
J. Sivic, A. Zisserman. (2003). Video Google: a text retrieval approach to object matching in videos. Proceedings of the Ninth IEEE International Conference on Computer Vision, vol. 2. ↩
-
H. Wu, R. Luk, K. Wong, K. Kwok. (2008). Interpreting TF-IDF term weights as making relevance decisions. ACM Transactions on Information Systems, vol. 26. ↩
-
L. Lamport. (1998). The Part-Time Parliament. ACM Transactions on Computer Systems 16, vol. 2, pp. 133-169. ↩
-
D. Ongaro, J. Ousterhout. (2014). In search of an understandable consensus algorithm. Proceeding USENIX ATC’14, pp. 305-320. ↩
-
C. Zauner. (2010). Implementation and Benchmarking of Perceptual Image Hash Functions. Master’s thesis, Upper Austria University of Applied Sciences. ↩
-
S. Choi, T. Kim, W. Yu. (2009). Performance Evaluation of RANSAC Family. Proceedings of the British Machine Vision Conference, vol. 24, pp. 1-12. ↩
-
D. Barath, J. Matas. (2017). Graph-Cut RANSAC. https://arxiv.org/abs/1706.00984 ↩